Can large fine-tuned language models imitate doctors?

Maxime Lewandowski
Machine Learning Engineer
TL;DR
Cedille is a new open source French language model created by Coteries. It is trained to understand and write French and is also the largest model of its kind for French. Cedille is trained using large databases of publicly available content on the internet filtered for toxic content.
Given a medical question, it's able to generate credible answers, but those answers are often wrong or unsafe. Using it to generate doctor answers is clearly out of question. However its ability to "understand" the question and give a short summary could be useful.
Cedille
Cedille is based on GPT-J, the 6 billion parameter model trained by the EleutherAI community. It is trained on 78 billion tokens (equivalent to 300 gigabytes of text) of French text from the C4 dataset. It took 12 days of computing on a v3-128 TPU to release the “Boris” version of the model, named after the famous French writer and singer Boris Vian.
What use case ?
At Nabla, we believe in asynchronous care which relies on messaging between patients and doctors. We have been working on providing our doctors super powers so that they can focus on the care with tools like autocompletion, fact extraction, categorisation... Most of these tools are text-based and use Natural Language Processing (NLP) models at some point of the process. Cedille claims to be the best model for French NLP and is in fact based on GPT-J which itself is inspired by the well-known GPT-3. These kinds of models are mostly used to generate text, but by tweaking them a bit, we can use them to extract data from text as well. Anyway, we had to test it and see what it's capable of.
Disclaimer
Nabla is a healthcare platform allowing users to chat with a medical team. All doctors are human doctors, the tools developed by the engineering team aim at helping doctors, not replacing them. All the data used in this experiment was carefully deidentified as required by law before it was handled by our data engineers.
The experiment
We are trying to generate a doctor's answer to a new patient question. The only context the model has is the text from the patient message. All examples below are anonymized versions of messages we received from patients.
We gave this model a question in the following form:
PATIENT: Je suis sous optimizette depuis plus d'un mois et j'ai des règles très irrégulières et quasi permanentes, est ce que c'est normal?DOCTOR:The DOCTOR: at the end of the input suggests to the model that this text needs to be completed by a doctor message. (The text generation is limited to 240 tokens for technical reasons, some messages will be cut short).
Using the model as is
Using Cedille out of the box gives OK results but messages don't look at all like messages from Nabla doctors and leak personal informations (Dr Charvet). Here are a few examples, messages on the right side have been generated by Cedille from the preceding patient message:


Fine tuning
Fine-tuning in NLP (Natural Language Processing) refers to the procedure of re-training a little bit of a pre-trained language model using your own custom data. As a result of the fine-tuning procedure, the weights of the original model are updated to account for the characteristics of the domain data and the task you are interested in.
In our experiment, we wanted the model to give answers that look like a certain type of Nabla doctor’s messages, with greetings and a reminder of the medical context. So we used all anonymised Nabla conversations of this type and show them to the model, expecting it to learn the style and tone of our amazing health team.
Fine-tuning Cedille to specialize it on a task is not straightforward. The model has about 24GB of weights and even in half precision will not fit in any modern GPUs for training (considering you have to load the optimizer and the gradients on the gpu too).
Using Deepspeed by Microsoft, we managed to offload the optimizer to the CPU as well as some parameters (at the cost of cpu / gpu bandwidth), and split the model to achieve model parallelism on two Nvidia Tesla A100.
We trained it for 2 epochs on about 6000 conversations.
Results
Here are a few examples of what our fine-tuned model can do in various situations. Messages on the right have been generated by our model from the preceding patient message.
Short and straightforward questions:
Example A.1 
Example A.2 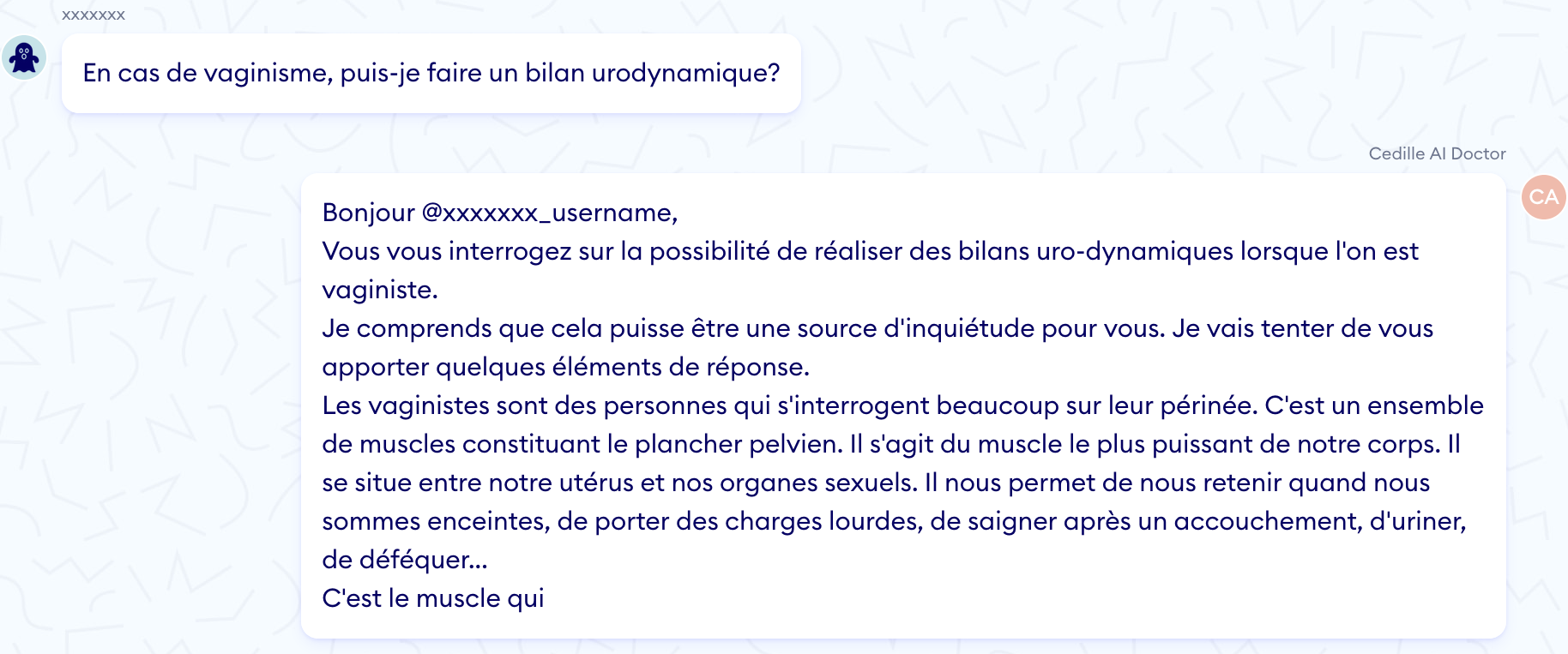
Example A.3 
Example A.4 
With these 4 example, we can notice:
- It writes coherent sentences with a coherent structure. Punctuation is good and makes for overall readable pieces of text.
- It can enumerate stuff in a list form and uses parenthesis for asides.
- It is able to output French letters like in Œstrogène or spermatozoïdes but only some of the times. Most of the time grammar and spelling is good.
- We can also see that it learned very well the structure of messages from Nabla doctors with greetings containing the username of the patient followed by a summary of the issue or question.
Now for the bad stuff:
- In example A.1 and A.2, it created the words "interniste" and "vaginiste" and their definitions it proudly gives, which is pretty bad.
- Past the first paragraph the model seems to improvise on subjects it has picked up in the question but doesn't really answer it.
Questions with a richer and more difficult context:
Example B.1.a 
Example B.1.b 
B.1.a seems to be a reasonable answer. The "summary of the question" part is great. It repeated explicit dates and almost got the implicit one (missed by a few days). But the rest of the messages missed the point again and just talks about global rules about the vaccine, not strictly related to the current question.
One good thing is that it got the "covid-19" context without any explicit mentions of it (only "Pfizer" and "pass sanitaire").
The real problem is exposed in example B.1.b which is another run of the same model that came with the same score which means that the model is as confident in the quality of both answers.
This time the model completely misses the point, hallucinating some questions about the vaccine safety.
Example B.2.a

Example B.2.b

Once again the beginning of the message is good in both versions but gives a completely unacceptable answer in B.2.a. B.2.b seems to go the right way but the model gave a higher confidence score to B.2.a.
Performance
Those generated answers take between 25 and 120 seconds (per message) to be generated on the best available GPU on Google Cloud Platform (Nvidia Tesla A100). It can be loaded on smaller GPUs in half precision, but requires a lot of work to make sure it will not run out of memory. Inference on CPU takes about 10 minutes or more for a single message (the decoding strategy has a huge impact on performance on CPU).
Conclusion
Large-scale language models are a hot topic because of how "smart" they seem at first glance, but people tend to vastly overestimate their reasoning abilities. In the healthcare context, suggesting complete doctor replies would not only be a waste of time, but also terribly unsafe: doctors would have to carefully filter out the nonsense in the generated answers.
Nevertheless, fine-tuning them for specific domains can already make them helpful for simpler tasks such as information extraction, summarization and conversational help. It's exciting to see how much performance improved compared to smaller, task-specific recurrent neural networks from just a few years ago.
Ecological note
Using and (mostly) training this kind of model requires a lot of computing power. During this experiment, we used resources from Google Cloud Platform and emitted an estimated 28.5kg of CO2eq, according to ML CO2 impact (same as driving for about 113km in an average car). This is low compared to what it could have been without using transfer-learning from the pre-trained model weights gracefully shared by Coteries AI.
Interested in this topic? Nabla is building a digital healthcare platform that is made affordable and scalable by machine learning. Come join us!