La sécurité et la confidentialité des données de Nabla.

Clément Baudelaire
ML Product Manager
La sécurité et la confidentialité des données occupent une place centrale dans la conception de nos produits.. Nous nous engageons à sécuriser les données des utilisateurs, à éliminer de potentielles vulnérabilités et à assurer la continuité du service.
Concrètement, nous utilisons un ensemble de technologies, de services et de procédures standards pour protéger les données contre l'accès, la divulgation ou l'utilisation non autorisés des données ainsi que contre la perte de données.
Nabla permet de générer des comptes rendus médicaux automatiquement pour permettre aux praticiens de consacrer toute leur attention au patient. Vous pouvez l'essayer gratuitement ici !
Cet article détaille comment les données sont recueillies, stockées et traitées lorsqu'un praticien utilise Nabla. Nous avons construit cet outil en garantissant le plus haut niveau de sécurité et de conformité avec la réglementation en vigueur, tout en veillant à ne jamais compromettre la qualité du compte rendu généré.
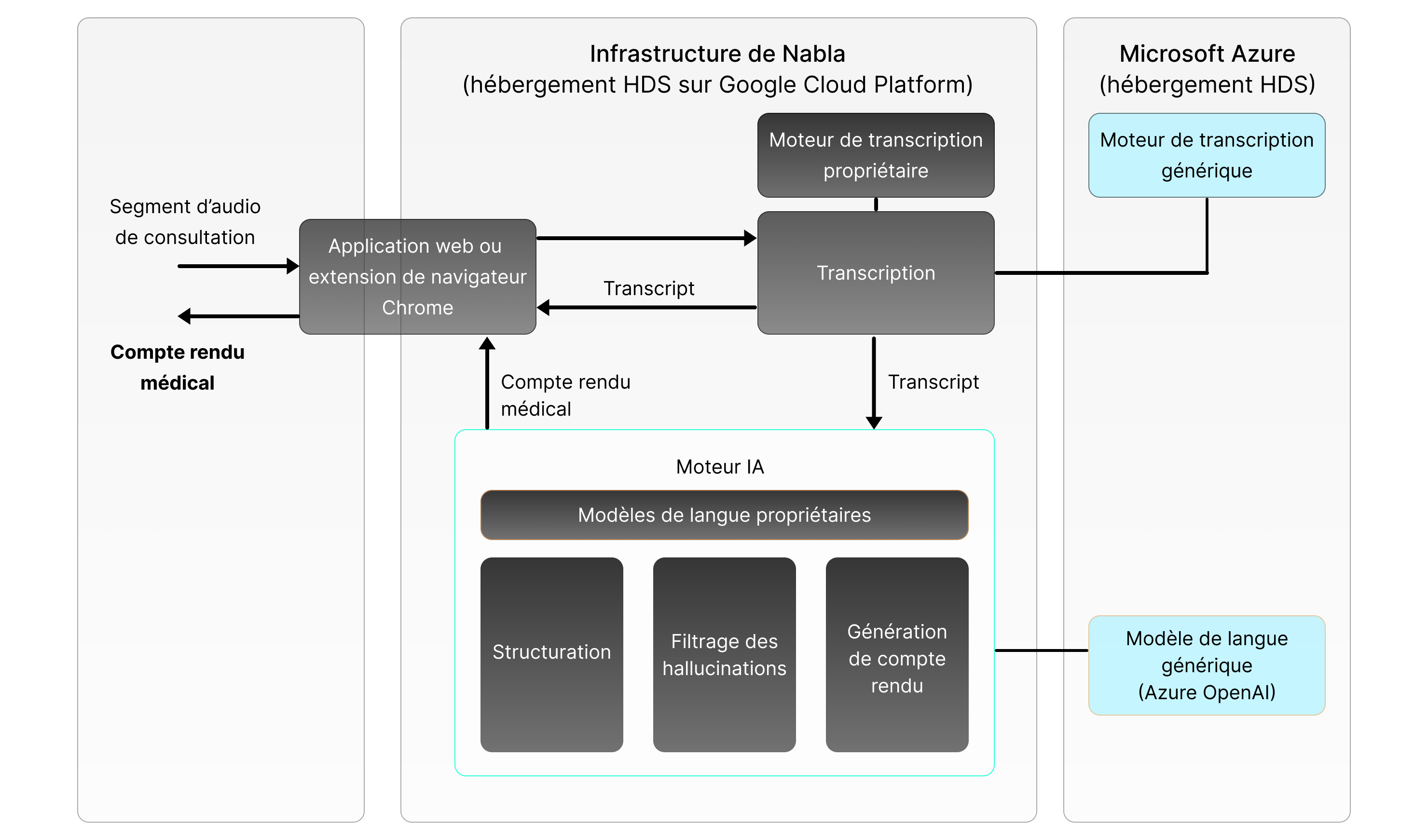
Chemin de données
Ce qu’il faut savoir en quelques mots : Nabla transforme la conversation médicale qui a lieu lors d'une consultation en un compte rendu médical structuré qui peut être exporté directement vers le logiciel patient du praticien.
En détail :
Depuis l’onglet du navigateur ou l'application mobile, Nabla capte l’audio de la consultation, lorsque le praticien commence à utiliser Nabla. L’audio n’est capté que si le praticien décide de cliquer sur le bouton pour commencer.
L'audio est ensuite transcrit en direct à l'aide d'une API de reconnaissance vocale.
Ce transcript est ensuite traité pour générer un compte rendu suivant la structure classique utilisée par les praticiens pour documenter les consultations, à l'aide d'une combinaison d'algorithmes internes de structuration du langage naturel et d'un modèle de langue de grande taille (LLM en anglais).
Voici un graphique résumant le chemin de données :
Stockage et traitement des données
La sécurité des données de santé est une priorité absolue pour Nabla, c'est pourquoi nous adoptons une approche aussi conservatrice que possible vis-à-vis de la conservation des données. Nous stockons les transcripts et comptes rendus générées temporairement, pour une durée configurable (14 jours par défaut). La seule exception concerne les données envoyées via l'outil de retour utilisateur (voir ci-dessous). Les enregistrements audio ne sont pas stockés. Nabla traite chaque segment d'audio individuellement et le supprime immédiatement. L'enregistrement intégral n'est stocké ni en mémoire vive ni sur disque.
L'objectif de cette période de stockage est de laisser suffisamment de temps aux praticiens pour relire, corriger et exporter les comptes rendus générées dans leur logiciel médical. Après expiration, les données sont immédiatements supprimées de l'application et ne subsistent que dans les sauvegardes de base de données. 7 jours plus tard, les sauvegards expirent à leur tour et aucune copie des données ne subsiste dans nos systèmes.
Tous les transcripts et comptes rendus sont protégés par deux couches de chiffrement (au niveau du système et de l'application), en utilisant des normes de cryptographie robustes.
Ce traitement des données est effectué sur l'infrastructure de Nabla dans Google Cloud Platform (GCP) et Microsoft Azure, en stricte conformité avec le RGPD et les normes d'hébergement HDS. Pour garantir que les données des patients ne soient jamais stockées en dehors de notre contrôle, nous avons également des accords pour assurer la non-conservation des données pour tous les services utilisés pour traiter celles-ci.
Retours & confidentialité
Pour offrir une meilleur expérience de support et améliorer Nabla au fur et à mesure du temps, nous permettons au praticiens de donner une note au compte rendu et d'envoyer un retour après chaque consultation. Ce mécanisme de retour est optionnel et peut être désactivé pour les organisations. Lorsqu'ils fournissent des retours, les praticiens peuvent choisir de joindre le compte rendu et la transcription générés. Nous utilisons un algorithme de dé-identification pour supprimer systématiquement toutes les parties des transcriptions et des comptes rendus contenant des informations personnellement identifiables avant de les stocker de manière permanente.
Voici un exemple de dé-identification :
"Je m'appelle Clément, je suis né le 16/06" devient "Je m'appelle [masked_name_001], je suis né le [masked_date_001]".
La version masquée est celle utilisée pour le support et l'entraînement de l'IA. Cela rejoint notre principe général : ne stocker que les données dont nous avons réellement besoin pour améliorer le produit. Stocker uniquement les retours dé-identifiés, et non pas toutes les données transitant par nos serveurs, nous permet de focaliser l'entraînement de l'IA sur les données ayant la plus grande valeur d'apprentissage pour nos modèles, et de minimiser les risques pour tous les utilisateurs. Cela donne également plus de contrôle aux organisations, qui peuvent choisir entre une version améliorée du support et des modèles d'IA, ou une politique de conservation des données plus stricte.
Sécurité de l'information
Afin d'assurer la sécurité des données traitées, Nabla s'appuie sur des processus et des systèmes à plusieurs niveaux.
Nous avons mis en place un programme complet de sécurité de l'information pour garantir un traitement sécurisé des données. Cela inclut la formation des employés, les audits externes et les tests d'intrusion, la gestion stricte des rôles et des permissions, des processus d'authentification robustes, le chiffrement au repos et en transit, la détection des vulnérabilités, la journalisation, la surveillance, l'alerte et bien plus encore.
Pour renforcer notre engagement, nous sommes en conformité SOC 2 Type 2 et également certifiés ISO 27001.
Plus de détails sont disponibles sur notre page consacrée à la sécurité.